Your cart is currently empty!
The foundation of Microsoft Fabric is a Lakehouse
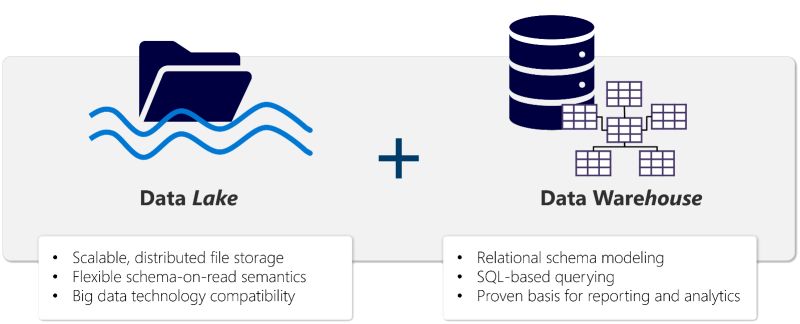
The foundation of Microsoft Fabric is a lakehouse, which is built on top of the OneLake scalable storage layer and uses Apache Spark and SQL compute engines for big data processing. A lakehouse is a unified platform that combines:
- The flexible and scalable storage of a data lake
- The ability to query and analyze data of a data warehouse.
A lakehouse presents as a database and is built on top of a data lake using Delta format tables. Lakehouses combine the SQL-based analytical capabilities of a relational data warehouse and the flexibility and scalability of a data lake. Lakehouses store all data formats and can be used with various analytics tools and programming languages.
In Microsoft Fabric, you can create a lakehouse in any premium tier workspace. After creating a lakehouse, you can load data – in any common format – from various sources; including local files, databases, or APIs. Data ingestion can also be automated using Data Factory Pipelines or Dataflows (Gen2) in Microsoft Fabric.
After you’ve ingested the data into the lakehouse, you can use Notebooks or Dataflows (Gen2) to explore and transform it.
Dataflows (Gen2) are based on Power Query – a familiar tool to data analysts using Excel or Power BI that provides visual representation of transformations as an alternative to traditional programming.
Data Factory Pipelines can be used to orchestrate Spark, Dataflow, and other activities; enabling you to implement complex data transformation processes.
After transforming your data, you can query it using SQL, use it to train machine learning models, perform real-time analytics, or develop reports in Power BI.